


DeepSeek et le paradoxe de Jevons
DeepSeek, une IA générative chinoise, a bouleversé le marché de l’intelligence artificielle depuis son lancement le 27 janvier 2025. En quelques jours, l’application est devenue la plus téléchargée sur l’App Store américain, dépassant ChatGPT développé par l’entreprise américaine OpenAI. Cette situation a relancé le débat sur la compétition technologique sino-américaine et pourrait entraîner une intensification des efforts en IA aux États-Unis.

Les investisseurs américains craignent la concurrence de DeepSeek, une IA made in China vantant un modèle low-cost. On commence à en savoir plus sur la start-up à l’origine de ce nouveau modèle d’IA, gratuit, ouvert et en accès libre. Le modèle open source sur lequel repose DeepSeek pourrait faire émerger une nouvelle économie de l’IA à bas coût.
Les accusations contre DeepSeek se sont intensifiées. OpenAI, la maison mère de ChatGPT, accuse la start-up chinoise d’avoir utilisé illégalement ses données pour entraîner son modèle. Selon OpenAI, DeepSeek aurait employé une technique de “distillation massive”, permettant à son IA d’apprendre efficacement à partir de ChatGPT. David Sacks, conseiller en IA de l’administration Trump, soutient ces allégations, affirmant que DeepSeek a “distillé des connaissances extraites des modèles d’OpenAI”. Microsoft et OpenAI auraient lancé une enquête pour vérifier si leurs données ont été obtenues de manière non autorisée. Cependant, aucune preuve concrète n’a été présentée publiquement pour étayer ces accusations. DeepSeek maintient sa transparence en publiant son code source, mais n’a pas rendu publiques ses données d’entraînement. Ces accusations ont conduit à des réactions gouvernementales. L’administration américaine examine l’impact de DeepSeek sur la sécurité nationale, tandis que la CNIL italienne a ouvert une enquête sur l’IA chinoise. il pourrait bientôt être interdit sur le sol américain. Un projet de loi récemment déposé prévoit des amendes et même des peines de prison pour ceux qui l’utilisent.
Développé par une start-up éponyme fondée par Liang Wengfeng, un prodige de la tech, et basée à Hangzhou, la « Silicon Valley chinoise » de l’est du pays, cet agent conversationnel offre de nombreuses fonctionnalités similaires à ses équivalents américains. DeepSeek a été lancé via un fonds spéculatif monté pour utiliser les mathématiques et l’IA dans le trading d’actions. High-Flyer a bâti son premier modèle d’IA en octobre 2016, avant de commencer à exploiter ces modèles pour développer presque toutes ses positions boursières en 2017. Il a ensuite recruté une équipe de recherche dédiée aux algorithmes d’IA. La conduite de recherches fondamentales en IA a permis à High-Flyer de devenir l’un des plus grands fonds quantitatifs du pays, selon l’hebdomadaire The Economist, avec un portefeuille passé de 1 milliard de yuans (130 millions d’euros) en 2016 à 10 milliards de yuans en 2019. L’ IA reste sous le joug de la censure chinoise. Interrogé, par exemple, sur le massacre de la place Tiananmen à Pékin, le 4 juin 1989, DeepSeek affirme ne pas pouvoir « répondre à cette question », expliquant être « guidé par des directives visant à éviter les sujets sensibles ou controversés, notamment ceux liés à des événements historiques ou politiques complexes ».
Interview de Liang Wenfeng, fondateur de DeepSeek, accordée à Waves en juillet 2024, sur le site de The China Academy
Un modèle économique qui peut être disruptif. Ce robot conversationnel a surpris les experts par sa capacité à rivaliser avec ses concurrents occidentaux, notamment dans l’écriture de codes complexes. DeepSeek a su exécuter parfaitement un programme de rétro-ingénierie sur différents outils développés par les Occidentaux. Alors que la tendance dans le secteur semblait aller vers une consommation exponentielle de données, réservant l’avenir de l’IA aux géants capables de financer des data centers toujours plus vastes, les ingénieurs de DeepSeek ont réussi à créer des produits d’IA à un coût bien inférieur à celui des hyperscalers américains.
Ses fondateurs affirment n’avoir investi que 5,6 millions de dollars pour le développer. Une somme dérisoire comparée aux milliards dépensés par les firmes de la Silicon Valley pour obtenir un résultat quasi similaire. Tandis que les chatbots américains ont été conçus avec des puces haute performance, auxquelles la Chine n’a pas accès, DeepSeek a recours à des puces H800 disponibles sur le marché chinois. L’IA chinoise a également un code source ouvert, ce qui permet à tout le monde d’y avoir accès et de le modifier, contrairement à ses rivaux qui ont développé des modèles propriétaires. Cela signifie que DeepSeek n’a pas besoin des GPU les plus performants pour fonctionner, ce qui lui permet de réduire ses coûts opérationnels et donc d’offrir des prix plus bas à ses clients.
Si les entreprises américaines comme OpenAI, Anthropic et Meta sont largement considérées comme dominantes, les États-Unis ont tenté de freiner les avancées chinoises en imposant des restrictions strictes sur l’exportation de puces d’IA et d’équipements semi-conducteurs. Dans un entretien accordé à Waves l’an dernier, Liang Wenfeng affirmait que les restrictions américaines constituaient le principal défi à surmonter pour DeepSeek : «L’argent n’a jamais été un problème pour nous. Le problème, c’est l’embargo sur les puces haut de gamme».
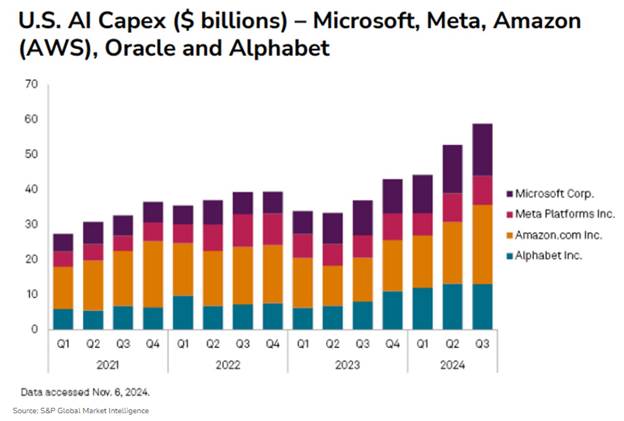
Aux États-Unis, le secteur de l’IA est récemment entré dans une phase d’investissement massive. Meta a confirmé la semaine dernière un budget de 60 à 65 milliards de dollars en dépenses d’investissement (Capex), tandis que Microsoft envisage de consacrer 80 milliards dans ce domaine. Parallèlement, le président américain a réaffirmé l’ambition du pays en matière d’IA en annonçant le projet StarGate, un programme massif de 500 milliards de dollars d’investissement dans les infrastructures d’IA au cours des prochaines années.
Deepseek a publié en code source libre, il n’a jamais rendu publiques ses données d’entraînement et reconnaît aussi utiliser ce qu’on appelle la distillation. Cela consiste à s’appuyer sur le savoir d’un modèle plus avancé pour entraîner rapidement un modèle plus restreint. C’est une technique classique que tout monde utilise notamment parce qu’on commence à manquer de données d’entraînement.
Comment fonctionne exactement la technique de distillation en IA ?
La distillation en IA est une technique de compression de modèle qui vise à transférer les connaissances d’un grand modèle (appelé “modèle enseignant”) vers un modèle plus petit (appelé “modèle élève”). Le processus se déroule en deux étapes principales :
- Entraînement du modèle enseignant : Un grand modèle pré-entraîné, généralement complexe et puissant, est utilisé comme point de départ.
- Transfert des connaissances : Le modèle élève, plus petit, est entraîné pour imiter les prédictions et les sorties du modèle enseignant. Cela se fait en utilisant les prédictions ou les probabilités de sortie du modèle enseignant comme données d’entraînement pour le modèle élève
Cette technique permet d’obtenir des modèles plus rapides à exécuter, plus économes en énergie et en ressources, tout en maintenant une performance proche de celle du modèle original.
Donald Trump a jugé que l’émergence de DeepSeek constituait un « avertissement » pour les industriels américains, les exhortant à « rester très concentrés sur la concurrence pour gagner ». La semaine dernière, le président américain a annoncé un plan de plus de 500 milliards de dollars pour renforcer l’IA aux États-Unis. De son côté, Tim Cook, lors des derniers résultats financiers d’Apple, a reconnu l’innovation dont DeepSeek a fait preuve en réduisant le coût de la formation et de l’exécution de son modèle V3 désormais en concurrence avec ChatGPT o3 : « En général, je pense que l’innovation qui stimule l’efficacité est une bonne chose, et, vous savez, c’est ce que vous voyez dans ce modèle. »
Un tournant dans l’économie de l’IA ?
Pour résumer, la « révolution DeepSeek » vient du fait que, dans sa dernière version, ce modèle affiche des performances proches de celles de la dernière version de ChatGPT, mais à un coût 20 à 30 fois inférieur pour le client. Le PDG d’OpenAI, Sam Altman, a publiquement reconnu les prouesses de DeepSeek-R1, tout en promettant une riposte avec des modèles encore plus avancés. Il y a deux ans, lors d’une conférence en Inde, Sam Altman rejetait avec assurance l’idée qu’une start-up émergente puisse ébranler la suprématie d’OpenAI. Selon lui, la formation des modèles de base nécessitait des ressources inaccessibles aux nouveaux entrants du secteur.
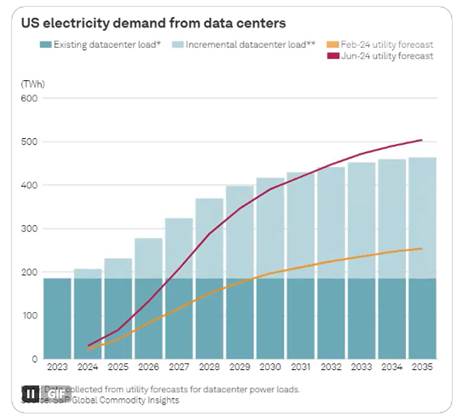
Alors que le fonctionnement de l’intelligence artificielle est très consommateur en énergie, promouvoir des modèles d’IA plus petits et plus adaptés aux besoins pourrait se révéler judicieux. L’électricité consommée par les centres de données numériques dans le monde devrait doubler d’ici à 2026, principalement en raison de l’essor de l’IA et des cryptomonnaies, selon un rapport publié le 24 janvier par l’Agence internationale de l’énergie. Ce besoin pourrait passer de 460 TWh en 2022, soit 2 % de la demande mondiale (dont 25 % pour les cryptomonnaies), à 1 050 TWh, soit un bond équivalent à la consommation d’un pays supplémentaire, de l’ordre de celle de l’Allemagne.
Deepseek aura prouvé qu’il est plus malin de s’appuyer sur ces modèles immenses que d’essayer d’en développer de nouveaux toujours plus gros. En tout cas, la course à l’IA va encore s’accélérer, toujours à l’initiative des Chinois. Car ces derniers jours, ce sont Alibaba et ByteDance, la maison mère de TikTok, qui viennent de lancer leurs nouveaux modèles d’IA. Là encore, annoncés comme plus performants.
L’IA n’est pas une mode passagère, et l’essor de DeepSeek ne fait que consolider sa place centrale dans l’évolution technologique et économique. DeepSeek abaisse les barrières à l’entrée, favorisant une adoption plus large. Contrairement aux craintes d’une saturation, plus l’IA devient accessible, plus son usage se multiplie, un phénomène observé dans d’autres révolutions technologiques et connu sous le nom du paradoxe de Jevons. Le paradoxe de Jevons énonce qu’à mesure que les améliorations technologiques augmentent l’efficacité avec laquelle une ressource est employée, la consommation totale de cette ressource peut augmenter au lieu de diminuer.
Bref, DeepSeek abaisse les barrières à l’entrée, favorisant une adoption plus large. Contrairement aux craintes d’une saturation, plus l’IA devient accessible, plus son usage se multiplie.
Les inconnues restent nombreuses autour de la start-up chinoise, mais d’autres annonces devraient suivre. Il est encore trop tôt pour se prononcer sur la viabilité de son modèle économique ou sur sa sécurité. Ce qui est certain, c’est que cela ne remet pas en cause la révolution liée à l’intelligence artificielle ; au contraire, cela devrait accélérer le processus en réduisant les barrières à l’entrée. Le nombre d’acteurs dans le secteur va croître plus rapidement qu’anticipé et les prix vont baisser.
L’affaire DeepSeek est d’une importance majeure, car elle pourrait avoir un effet déflationniste et impacter l’ensemble de la chaîne de valeur. D’un point de vue macroéconomique, cela pourrait être une bonne nouvelle. Toutefois, pour certaines entreprises, les modèles fondés sur des taux de croissance et des marges insolentes pourraient être remis en cause.
Si les nouvelles versions du fabricant chinois ont ébranlé les investisseurs de certaines entreprises, elles devraient être une source d’optimisme pour le monde entier notamment pour l’Europe qui semblait en queue de peloton mais qui pourrait elle aussi restée dans la course. DeepSeek démontre comment la concurrence et l’innovation peuvent rendre l’IA moins chère et donc plus accessible et utile.
{kind=link}